Сценарии использования
Фреймворк может найти достаточно широкое распространение. Несмотря на то, что основной задачей фреймворка являлась автоматизация процесса разработки программ роботизированной сборки, программное обеспечение может применяться также и для других задач.
В частности,
- веб-сервис с модулями генерации датасетов и интерфейсом создания новых навыков может применяться для запуска любых других поддерживающих API навыков, не связанным напрямую с задачей сборки изделий;
- модуль исполнения программ ROS 2 включает в себя довольно гибкую систему управления исполнением с помощью деревьев поведения и может быть применён к любым задачам планирования, требующих модульности и реактивности;
- для студентов, исследователей и инженеров фреймворк может упростить разработку и отладку программного обеспечения за счёт использования функций высокого уровня абстракции при решении задач манипулирования.
Ниже рассмотрены сценарии использования, которые были разработаны командой Robossembler.
Обучение с подкреплением - rbs_gym
Модуль rbs_gym предназначен для реализации среды обучения с подкреплением для роботов-манипуляторов. Он активно использует возможности открытой библиотеки Робосборщик, упрощая управление сценой и настройку среды.
Основные компоненты модуля обеспечивают:
- получение пространства наблюдения,
- передачу управляющих сигналов агенту,
- рандомизацию параметров среды,
- настройку задач, определяющих награды и условия для агента.
Пространства наблюдения и действий
Пространство наблюдения включает:
- скорость на эффекторе робота,
- положения суставов робота,
- изображения с камеры (глубина, цвет или облака точек).
Пространство действий позволяет:
- отправлять управляющие сигналы в виде усилий или скоростей в пространстве задач робота,
- управлять положением захватного устройства,
- задавать усилия в конфигурационном пространстве робота.
Гибкая настройка агентов
В составе модуля реализован класс ExperimentManager, который управляет предварительной настройкой агентов обучения. Конфигурации описываются в формате YAML. Пример гиперпараметров для алгоритма TD3 доступен здесь.
Поддерживаются следующие алгоритмы обучения:
Общая структура и примеры
Общий вид среды обучения для задачи достиженая точки пространства представлен на изображении:

Общий вид среды для задачи "достижения точки" в rbs_gym
На рисунке точка отмечена зеленым шаром. Каждую эпоху обучения выбираются разные позиции для робота в конфигурационном пространстве, а также позиция объекта выбирается случайным образом.
Диаграмма классов на примере задачи Reach детализирует архитектуру модуля:
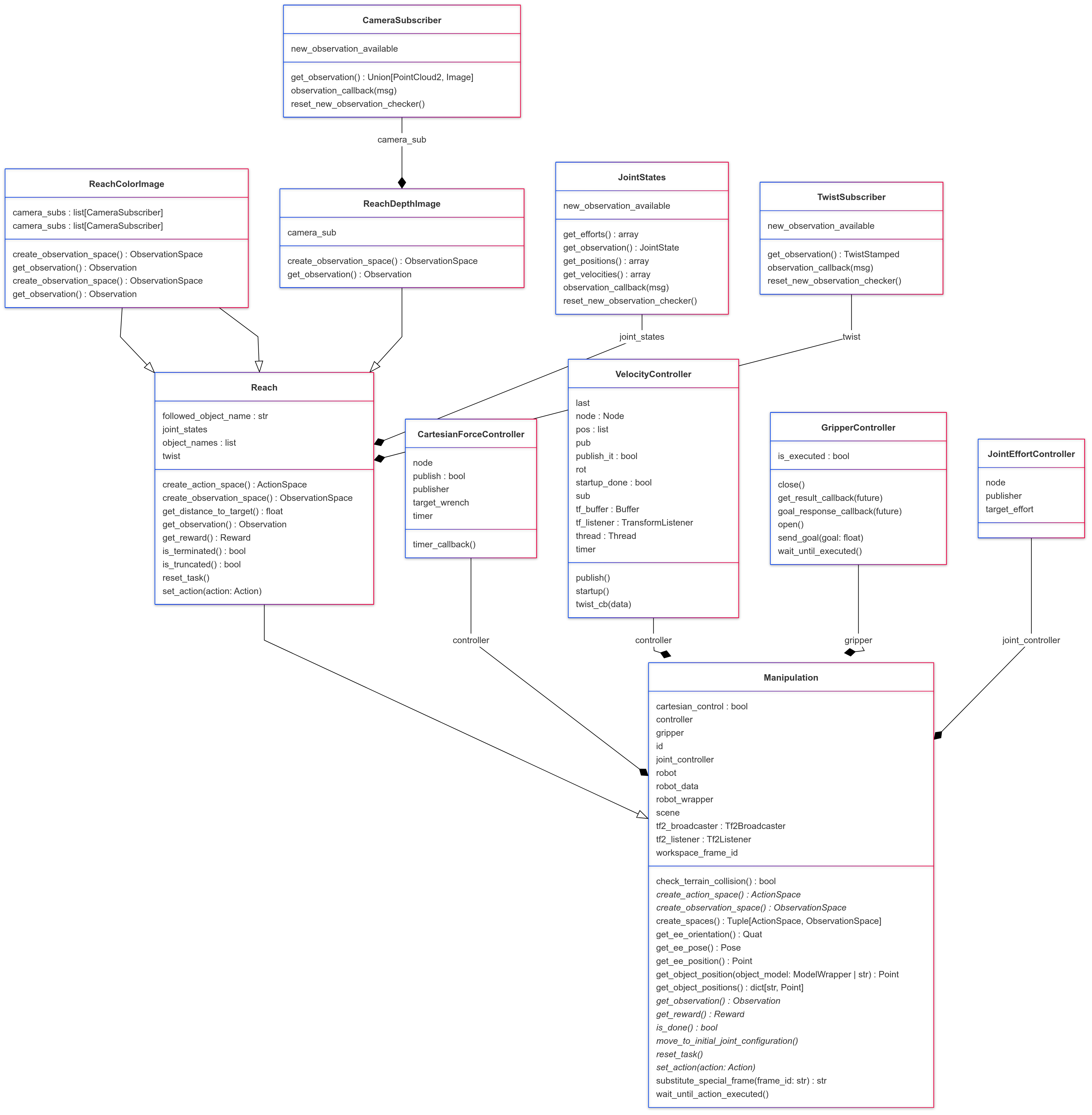
Диаграмма классов для задачи Reach
Агент использует усилия в пространстве задач для достижения до точки.
Управляющие сигналы:
где — компоненты силы.
Пространство наблюдения:
где:
- — положение эффектора робота,
- — положение цели,
- — пространственный вектор скорости эффектора.
Функция наград:
- За уменьшение дистанции до цели:
где — число шагов, — расстояние до цели, .
- За коллизии:
где — пространство коллизий.
- Штраф за медленное выполнение задачи:
- Бонус за достижение цели:
Результирующая награда:
Агент считается обученным, если за эпизод.
Тестирование и результаты
На графике представлены результаты обучения:
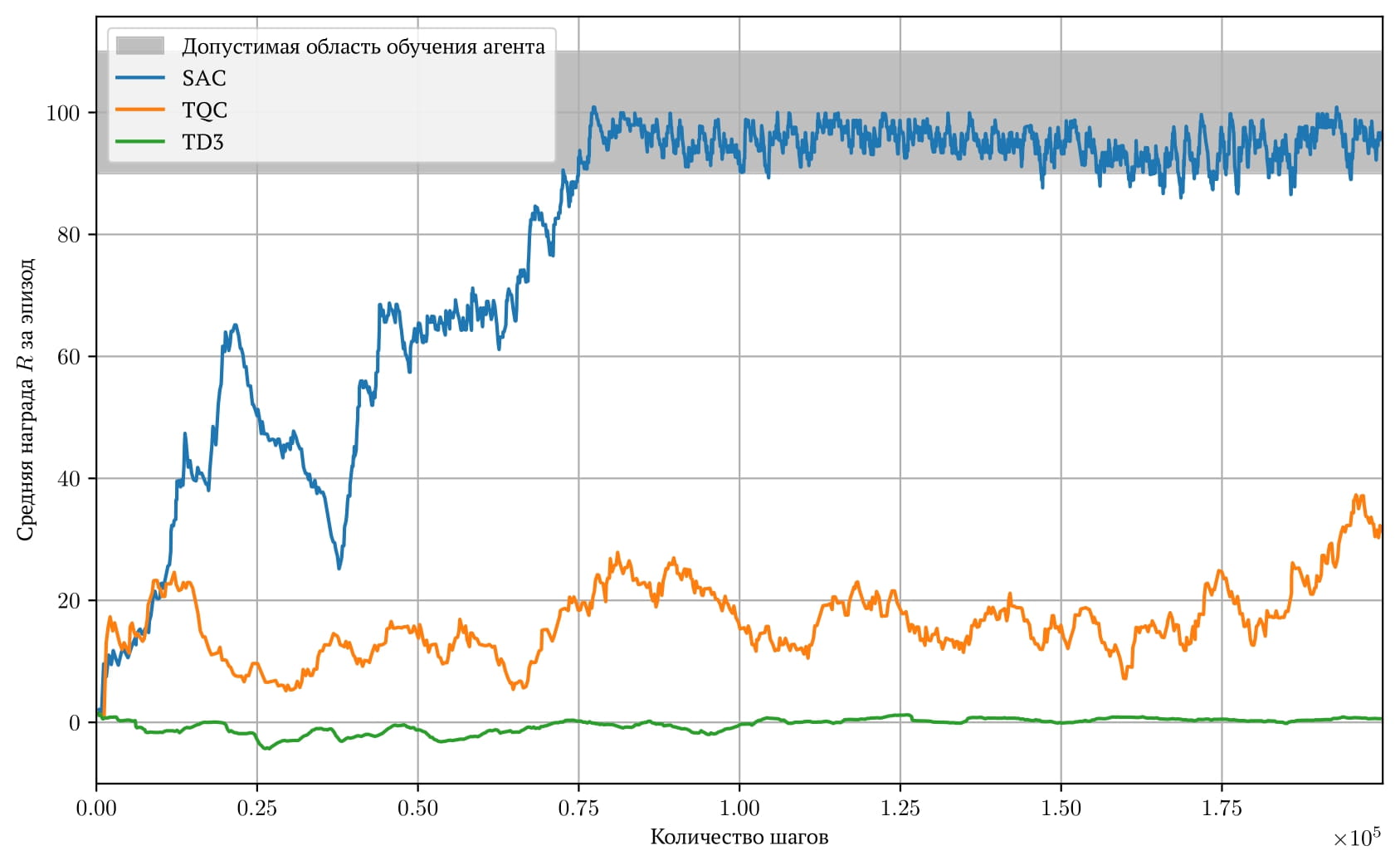
Графики обучения. Допустимая область (100 ± 10) показывает диапазон, при котором агент считается обученным.
Самостоятельный запуск обучения
Для самостоятельно запуска этого примера следуйте инструкции.
Имитационное обучение с помощью деревьев поведения
Описанный выше модуль rbs_gym также можно использовать для более специфических сценариев применения - в частности, для имитационного обучения, где обучение с подкреплением дополняется демонстрациями, полученными в симуляторе или с помощью устройств телеуправления роботом. Ниже приведена диаграмма ориентировочной реализации такого сценария, на которой отражены основные модули системы и их взаимосвязи.
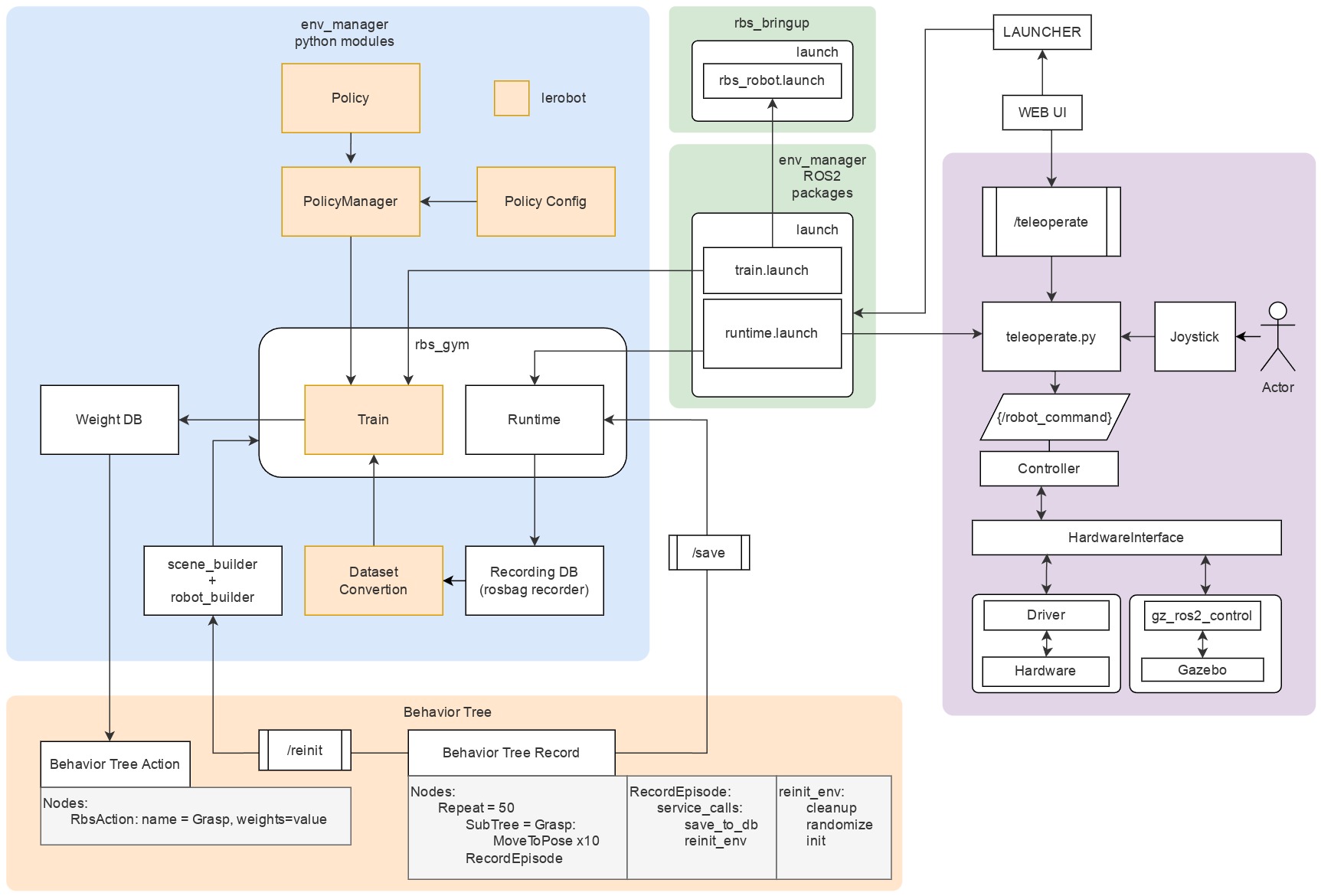
На диаграмме показано каким образом программные модули фреймворка bt_executor, scene_builder, rbs_runtime, env_manager интегрируются со сторонними библиотеками - в частности, с библиотекой lerobot, из которой используются модули для формирования Policy, обучения и конвертации датасета. На диаграмме также выделены примитивы дерева поведения, среди которых можно отметить RecordEpisode, осуществляющий запись демонстраций в runtime в цикле.